type
Post
date
Dec 17, 2025
slug
llm/learning/3Blue1Brown/chapter4
summary
3Blue1Brown LLM 相关视频的笔记
status
Published
tags
LLM
AI
category
技术茶点
icon
password
3Blue1Brown LLM 相关视频的笔记
3Blue1Brown YouTube 主页



Backpropagation calculus | Deep Learning Chapter 4
反向传播并不是在算答案,而是在算:“每个参数,应该朝哪个方向动,动多少,才能让损失下降得最快”
反向传播不是新算法,是链式法则的系统化执行
梯度不是公式,是“敏感性”,现代深度学习 = 自动微分 + 数值工程
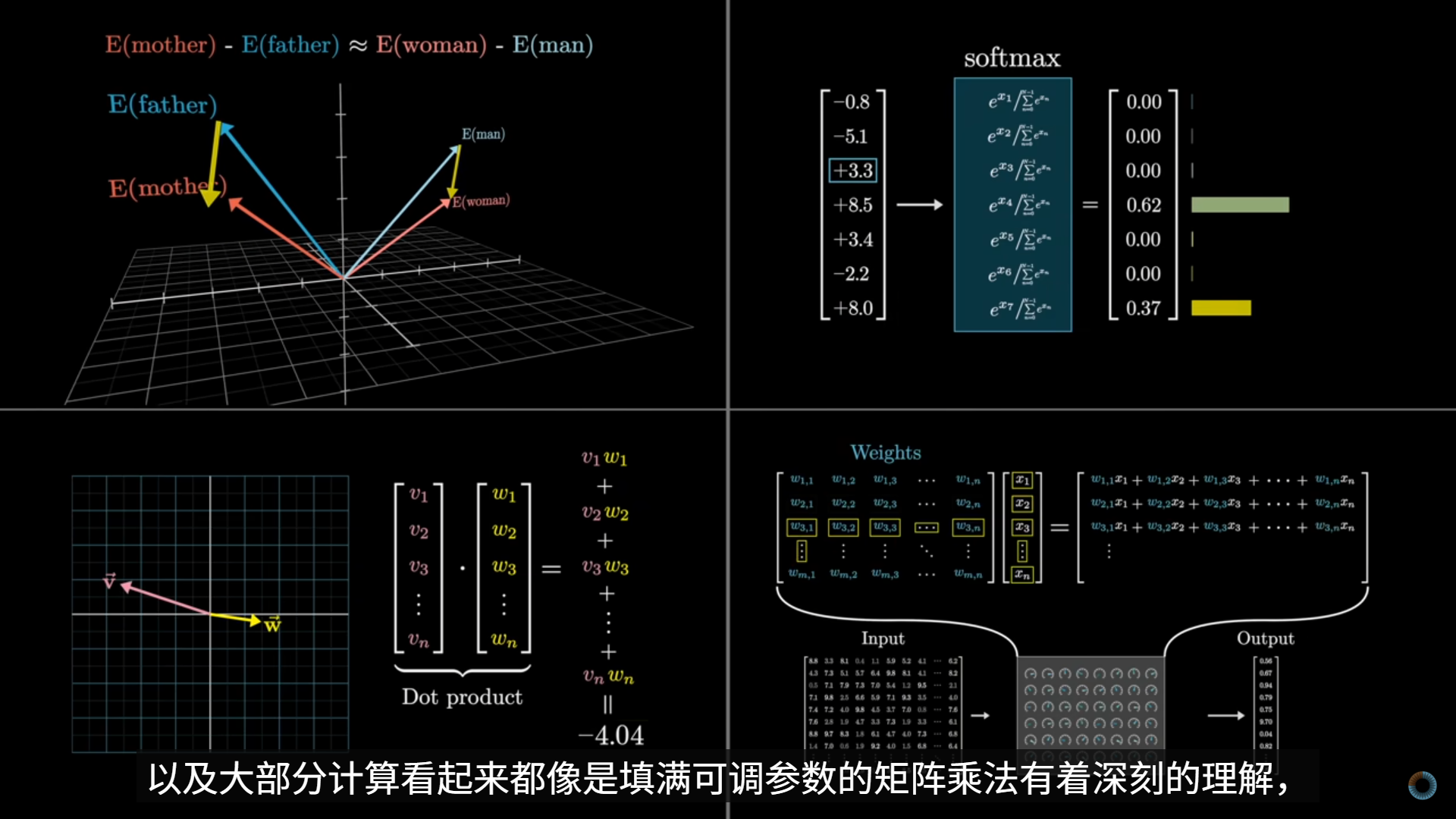
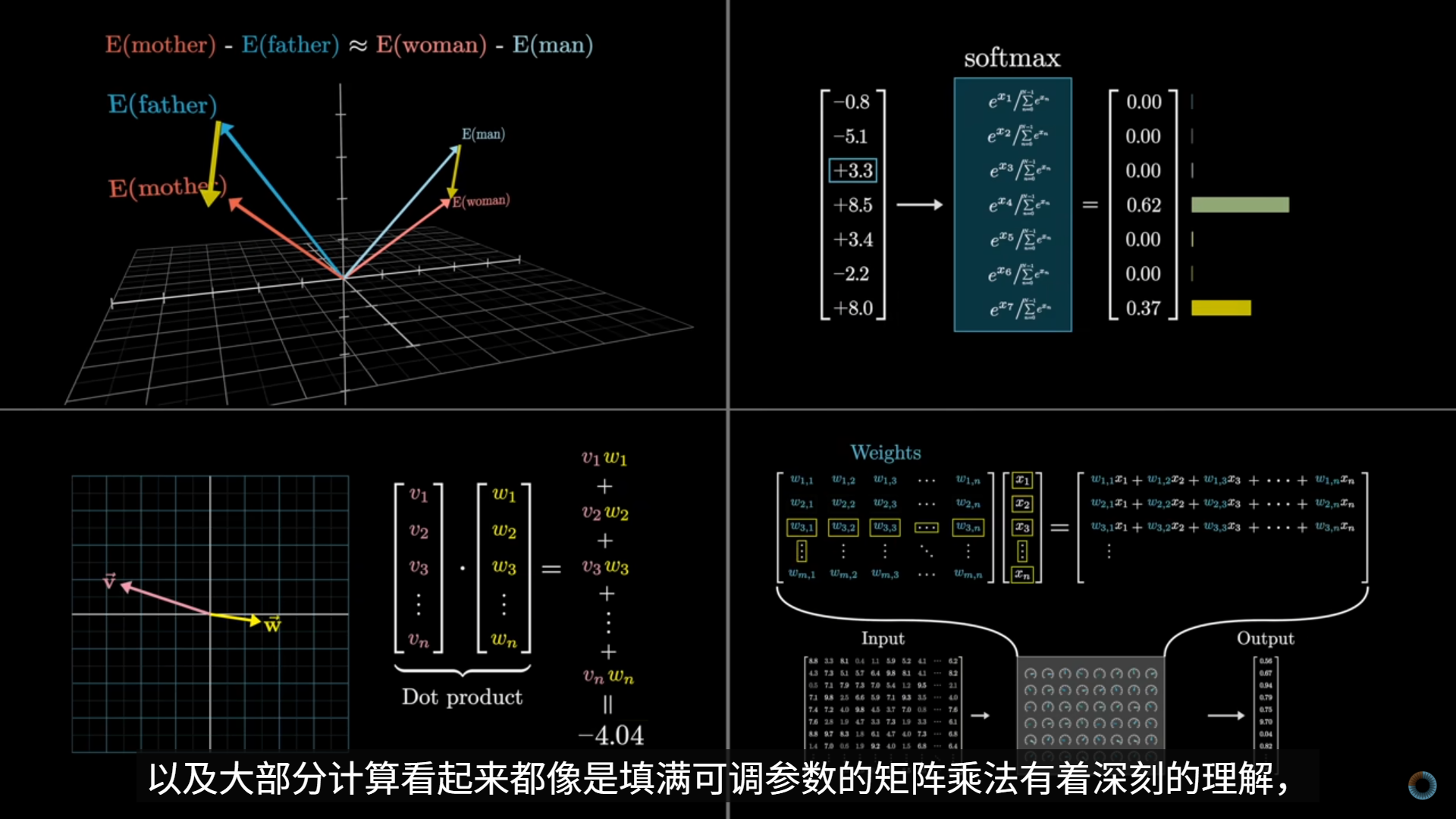
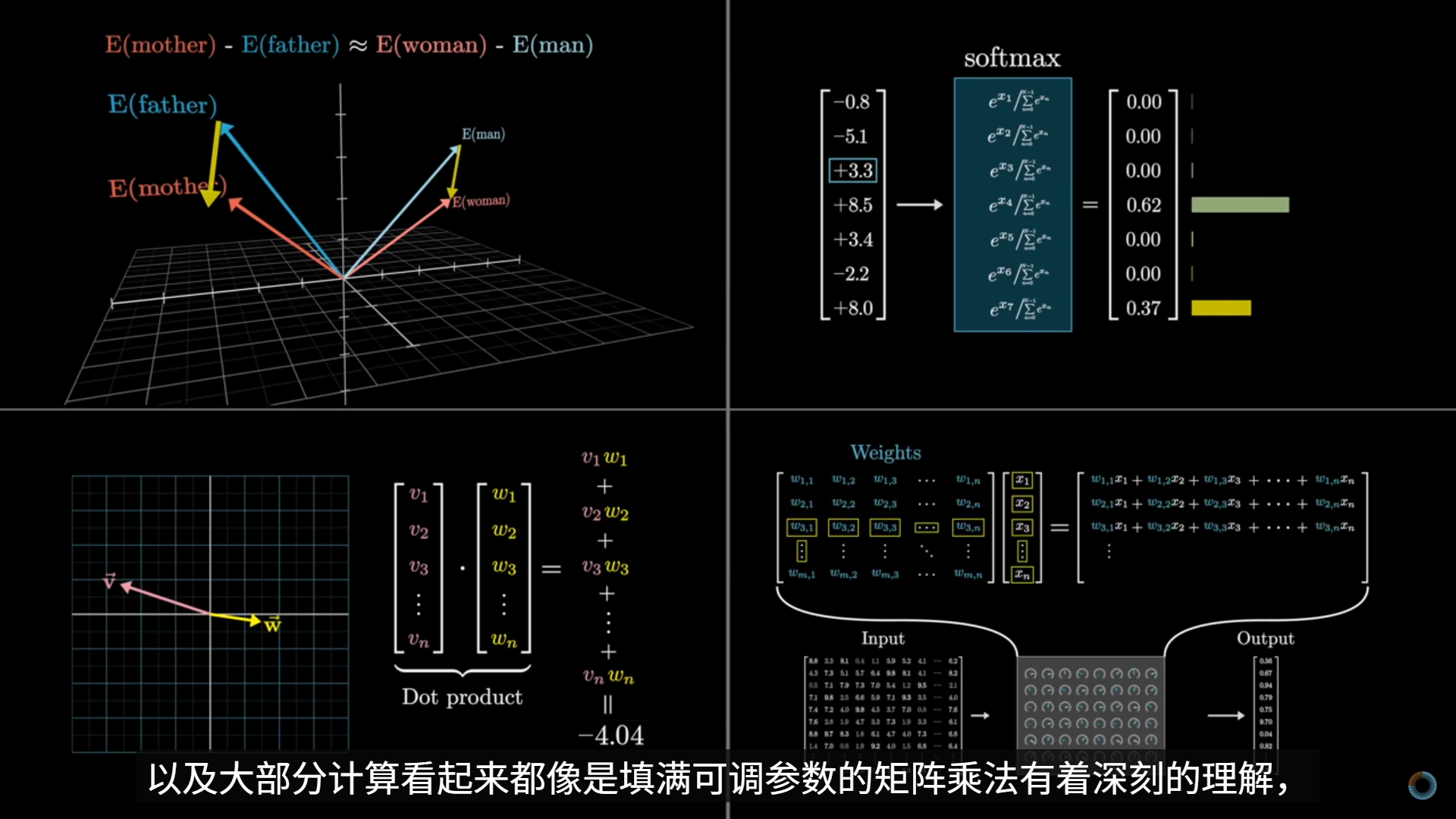
- 神经网络中的链式法则
- 如果我把某个参数(w 或 b)轻微拨动一下,最终的损失 C 会往哪个方向、变多还是变少?

- 计算
- 以仅有一元的情况示例,只保留 一个输入、一个权重、一个偏置、一个输出
- w→z→a→C
- 只有 两个可学习参数:w、b;目标:让 C 变小
- 我们不是“解函数”,只是问:w 往哪边动,C 会下降
- 步骤
- 1、拆成链条
- 2、逐个求偏导
- 3、合并
- 4、梯度下降参数更新
- 为什么现代框架不再手算
- 规模增大,数学立刻崩溃
- 导数公式 ≠ 可执行程序
- 中间变量如何缓存?
- 计算顺序如何最省显存?
- 哪些梯度可以复用?
- 哪些子图可以并行?
- 反向传播本质是“图算法”,不是“微积分题”
- 前向:
- 构建计算图(DAG)
- 缓存中间值
- 反向:
- 从 loss 节点反向遍历图
- 对每个算子调用本地梯度规则
- 只需要“局部规则”,不用全局公式
- 加法:梯度怎么传
- 乘法:梯度怎么传
- sigmoid:梯度怎么算
- matmul:梯度怎么算
- 数值稳定性与工程优化,只要算子是可微的,框架就能自动反







- 反向计算
- 从一元推广到多层神经网络



- Author:沈林曦
- URL:https://blog.aibhtt.com/article/llm/learning/3Blue1Brown/chapter4
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts