type
Post
date
Dec 16, 2025
slug
llm/learning/3Blue1Brown/chapter3
summary
3Blue1Brown LLM 相关视频的笔记
status
Published
tags
LLM
AI
category
技术茶点
icon
password
3Blue1Brown LLM 相关视频的笔记
3Blue1Brown YouTube 主页



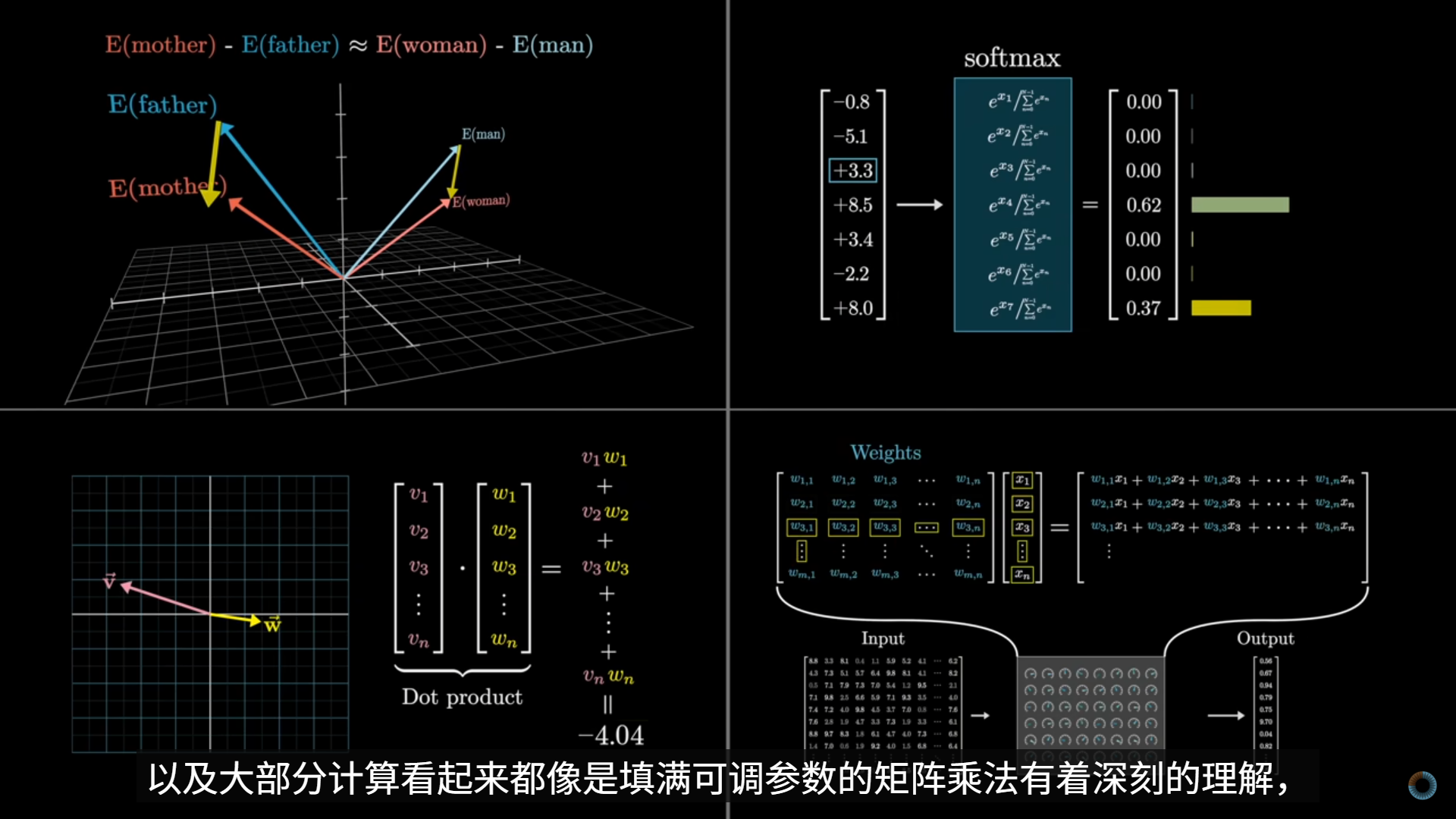
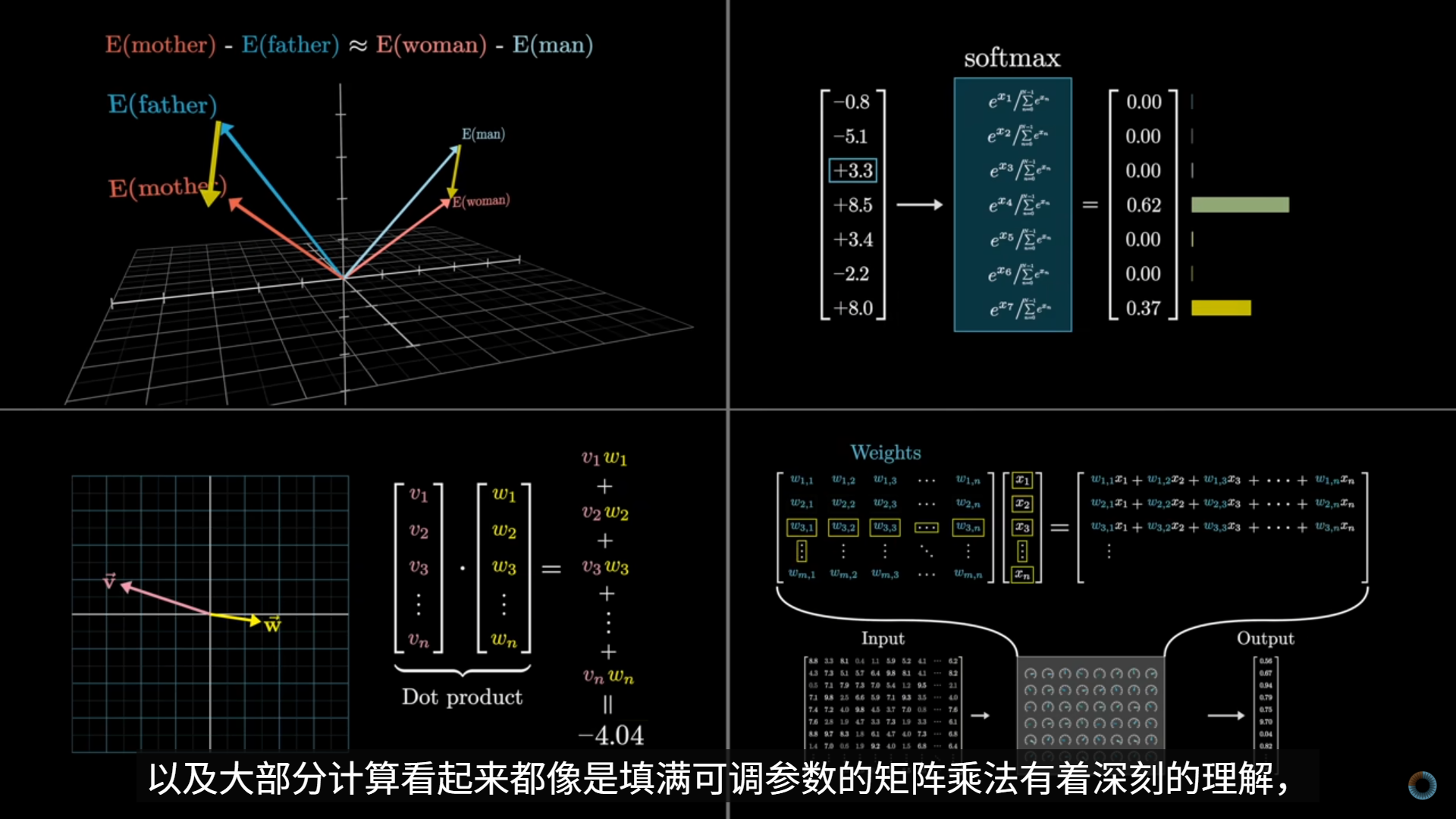
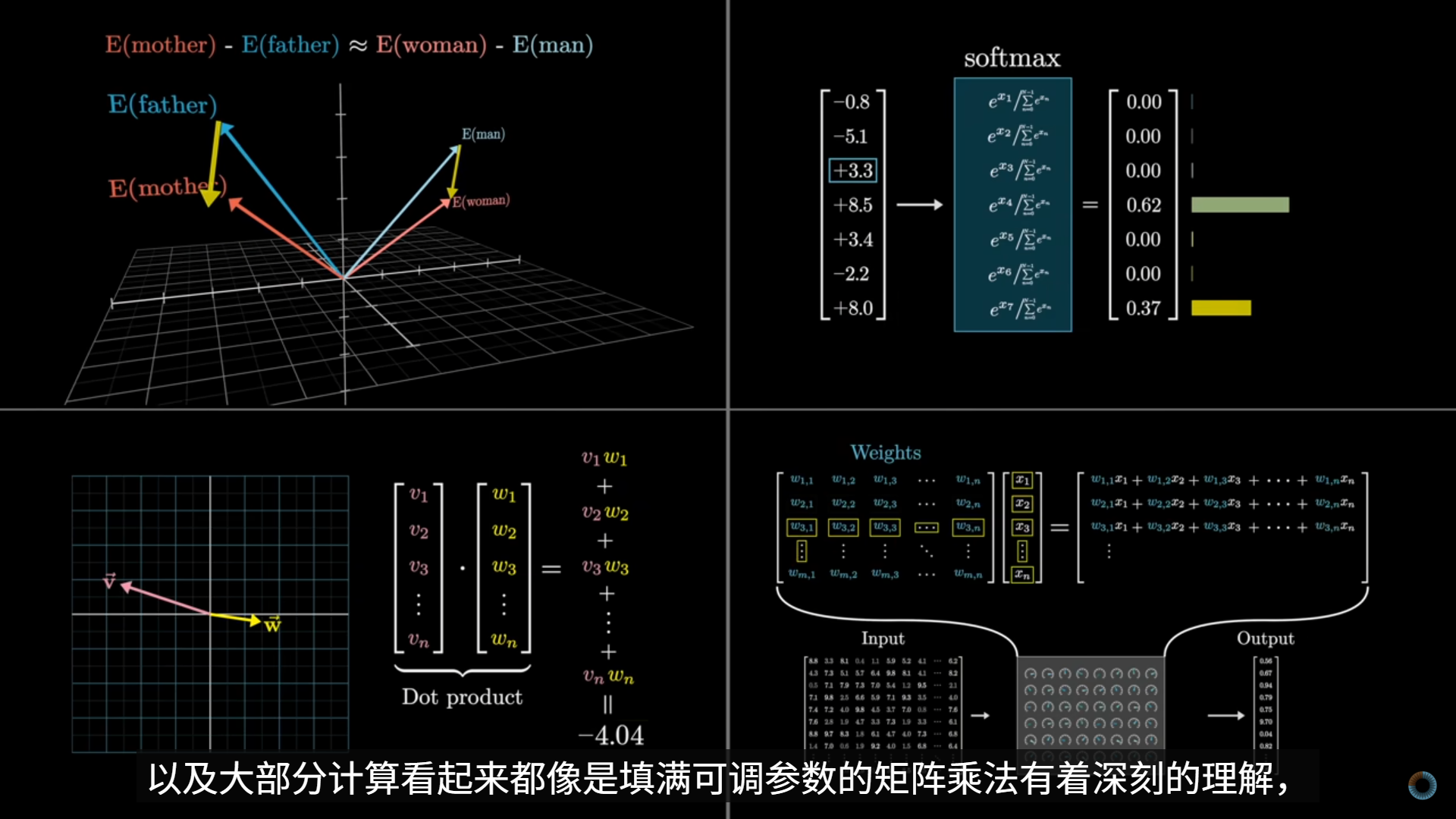
Backpropagation, intuitively | Deep Learning Chapter 3
反向传播的直观目的,是回答这样一个问题:
某一个训练样本的预测误差,究竟应该如何“分摊”到网络中每一个权重和偏置上?
即输出层错了多少 → 每一层的参数各自“该负多少责任”。
- 反向传播的直观演示
- 每一个训练样本会对权重偏置的调整造成怎样的影响?
- 在理论上,代价函数通常定义为整个训练集(或一个 batch)上误差的平均值;但在实际计算梯度时,反向传播是针对单个样本或小批量样本进行的,然后再对梯度取平均,用于更新参数
- mini-batch SGD
- 成本函数涉及成千上万个训练样本的成本取平均值,所以调整每一步梯度下降用的权重偏置也会基于所有的训练样本
- 神经网络不能直接调节神经元的激活值,因为激活值是前向传播的计算结果;但我们可以根据“希望输出如何变化”,反推出哪些参数的变化会促成这种变化。
- 哪些变大、哪些变小
- 改变的方式
- 增加偏置量
- 增加某个神经元的偏置,会整体性地提高该神经元的激活值;因此,如果希望某个神经元“更容易被激活”,偏置就是最直接的调节参数。
- 增加权重
- 不同神经元的权重影响力是不同的——与多大的激励值相乘
- 调整某条连接的权重,会影响上一层某个神经元对当前神经元的贡献程度。权重的“影响力”不仅取决于权重本身,还取决于该权重连接的上一层激活值有多大
- 改变上一层的激活值
- 依据对应权重大小对激活值做出呈比例的改变
- 虽然不能直接修改上一层的激活值,但可以通过修改更早层的权重和偏置,间接改变这些激活值。反向传播正是沿着这一依赖链条,逐层向前传递“应该改变多少”的信息。
- 梯度下降
- 不仅关心参数增大还是减小,也关注哪个参数的性价比最高(赫布理论)
- 梯度下降不仅关心参数应该增大还是减小,更关心:单位参数变化,能够带来多大幅度的代价下降。
- 以单个手写”2“为例
- 将所有期待的改变相加,得到一串倒数第二层改动的变化量
- 重复这个过程,改变影响倒数第二层神经元激活值的相关参数
- 循环…
- 对所有其他训练样本(”2“以外)同样做一遍反向传播
- 取平均值
- 随机梯度下降——提高计算速度
- 在实际训练中,这一反向传播过程会对多个训练样本(一个 batch)重复执行,然后对这些样本产生的梯度取平均,用于一次参数更新。
- 当 batch 规模较小时,这种方式被称为随机梯度下降(SGD)或小批量梯度下降(mini-batch SGD),它在计算效率和优化稳定性之间取得平衡。





总结“当模型错了,我们如何有条不紊地把‘错因’分配给网络中每一个参数”尽管现代大模型拥有极其复杂的结构和海量参数,但其训练时的核心误差信号传递方式,依然遵循这一章中所展示的反向传播思想。所谓“大模型”,并不是改变了学习原理,而是将同一套反向传播机制扩展到了前所未有的规模。
- Author:沈林曦
- URL:https://blog.aibhtt.com/article/llm/learning/3Blue1Brown/chapter3
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts