type
Post
date
Dec 17, 2025
slug
llm/learning/3Blue1Brown/chapter7
summary
3Blue1Brown LLM 相关视频的笔记
status
Published
tags
LLM
AI
category
技术茶点
icon
password
3Blue1Brown LLM 相关视频的笔记
3Blue1Brown YouTube 主页


章节 | 内容核心 |
Deep Learning Chapter 1 | 什么是神经网络 |
Deep Learning Chapter 2 | 梯度下降、神经网络如何学习 |
Deep Learning Chapter 3 | 反向传播直观理解 |
Deep Learning Chapter 4 | 反向传播 微积分细节 |
Deep Learning Chapter 5 | Transformer 与 LLM 介绍 |
Deep Learning Chapter 6 | 注意力机制详解 |
Deep Learning Chapter 7 | 变压器中如何存储知识/事实 |
Additional | Diffusion Models、图像生成等解释 |
How might LLMs store facts | Deep Learning Chapter 7
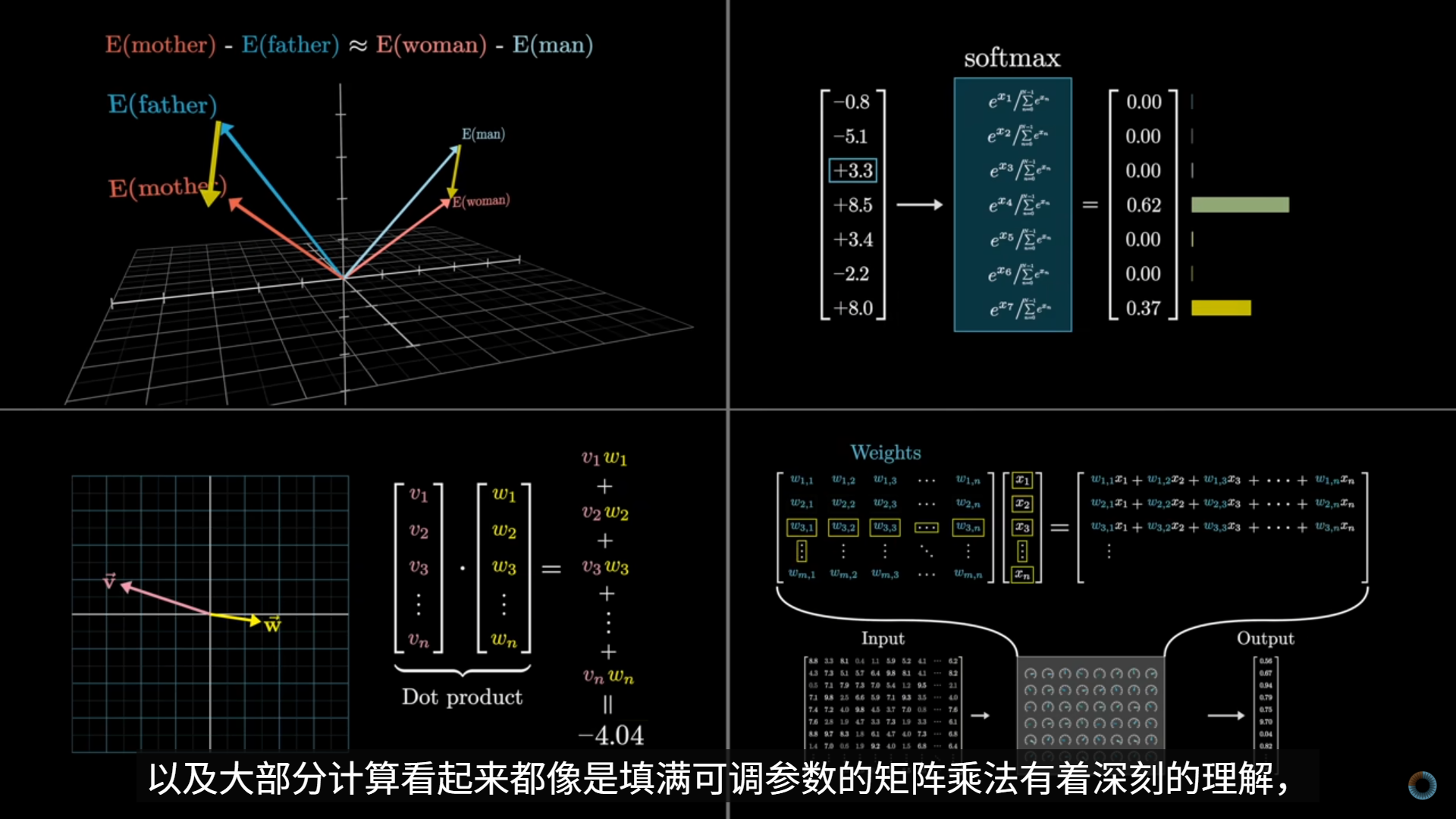
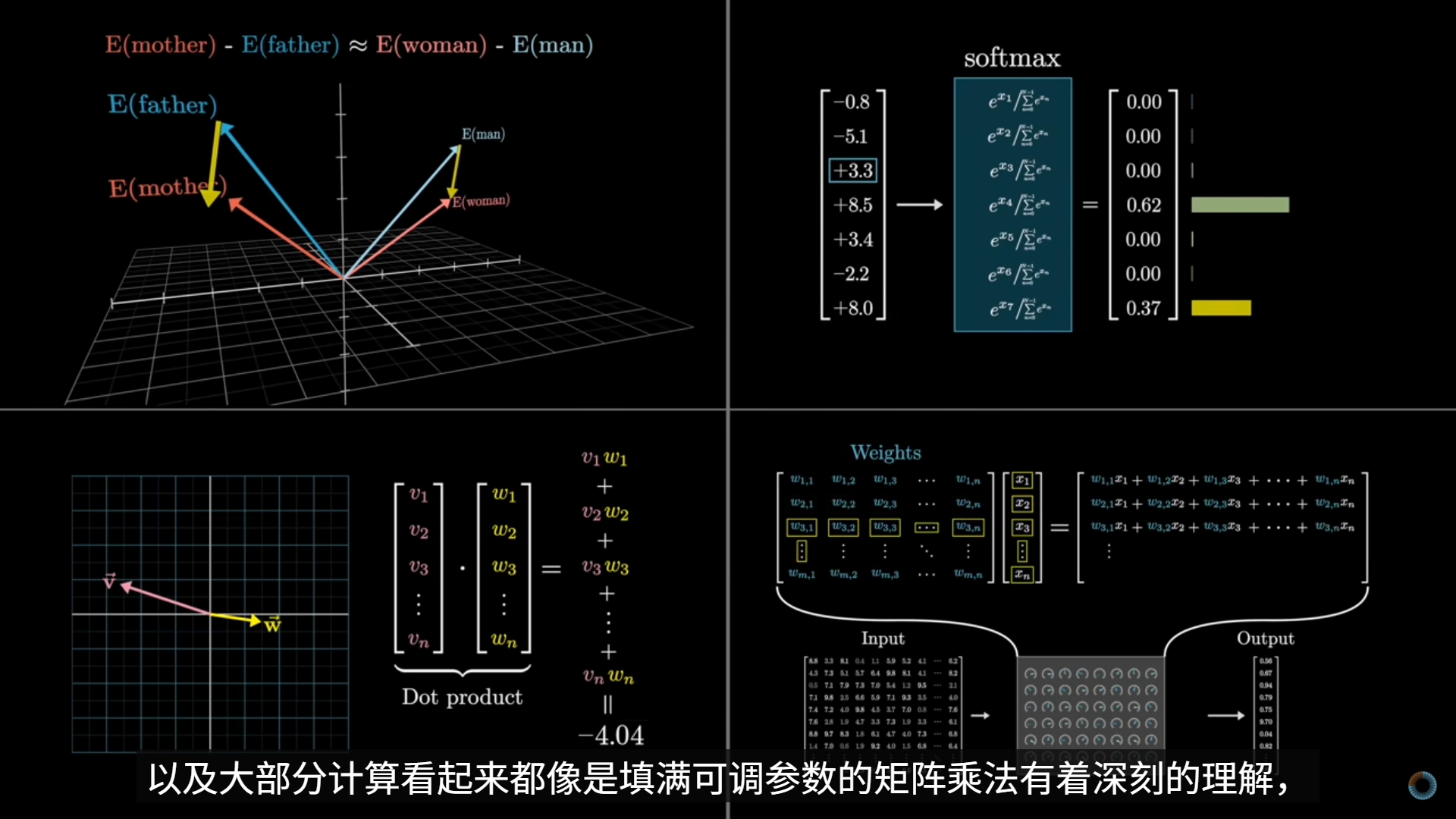
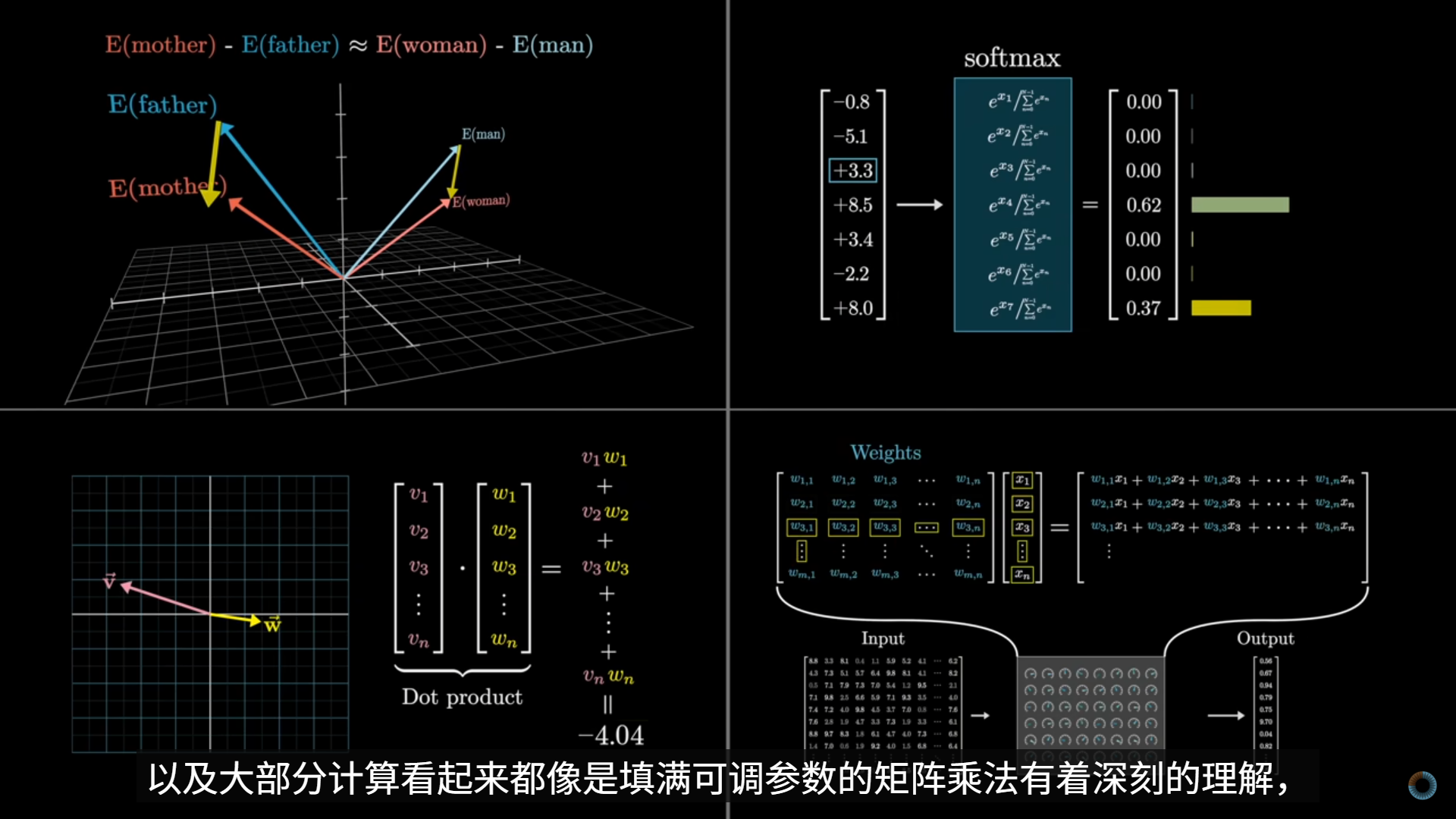
回顾:每一个词都需要编码远远超出一个词的含义的东西——足以预测接下来会发生什么。LLM 并不是“存储事实”,而是“学会了一种生成事实的函数结构”。
一个事实,体现为在大量上下文下,模型倾向于产生一致输出的参数结构,且这个事实不是局部存储的。


在 Transformer 中,每一层包含:
- Attention
- MLP(Feed Forward Network)
MLP 层比 Attention 更“像是在承载事实模式”
- MLP 是逐 token 的非线性映射
- 能把一种表示稳定地映射成另一种表示
- 非常适合学习:
- “某类上下文 → 某类输出倾向”
- 这不是显式存储
- 而是函数形状的体现
为什么微调不能当“改数据库”用
- 微调改变的是整个函数空间
- 不是单条事实
- 容易引发灾难性遗忘
为什么 RAG 是必要的
- LLM 擅长生成
- 不擅长精确存储
- 外部知识库提供:
- 可控
- 可更新
- 可审计的事实来源
为什么“让模型记住新知识”这么难
- 你在试图改一个连续函数
- 而不是插入一条记录
But how do AI images and videos actually work? | Guest video by Welch Labs
- 可迭代的过程


- Author:沈林曦
- URL:https://blog.aibhtt.com/article/llm/learning/3Blue1Brown/chapter7
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts