type
Post
date
Dec 17, 2025
slug
llm/learning/3Blue1Brown/chapter6
summary
3Blue1Brown LLM 相关视频的笔记
status
Published
tags
LLM
AI
category
技术茶点
icon
password
3Blue1Brown LLM 相关视频的笔记
3Blue1Brown YouTube 主页



Attention in transformers, step-by-step | Deep Learning Chapter 6
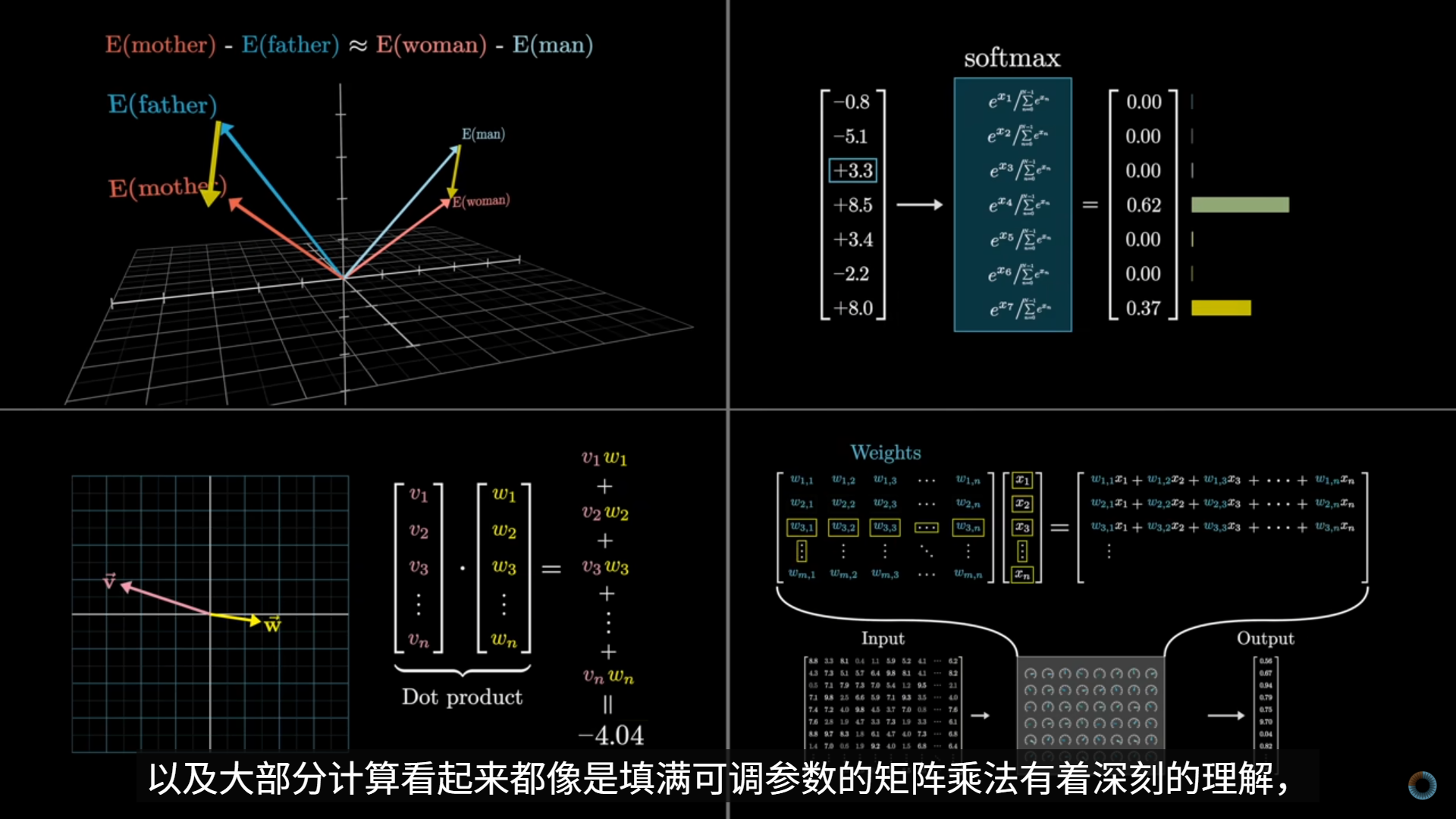
1️⃣ Attention 不是选信息,而是“按相关性混合信息”
2️⃣ QKV 只是同一个向量在不同子空间里的表达
3️⃣ Transformer 的核心能力是:让输入内部建立动态关系
Attention = 根据“相关性”动态混合信息
- 不再用固定权重
- 不再假设“每个输入都同等重要”
- 而是:针对当前目标,临时决定谁重要
Transformer 用的不是“对外注意力”,而是 Self-Attention
- 同一句话里的每个 token
- 都会看同一句话里的所有 token
- 包括自己
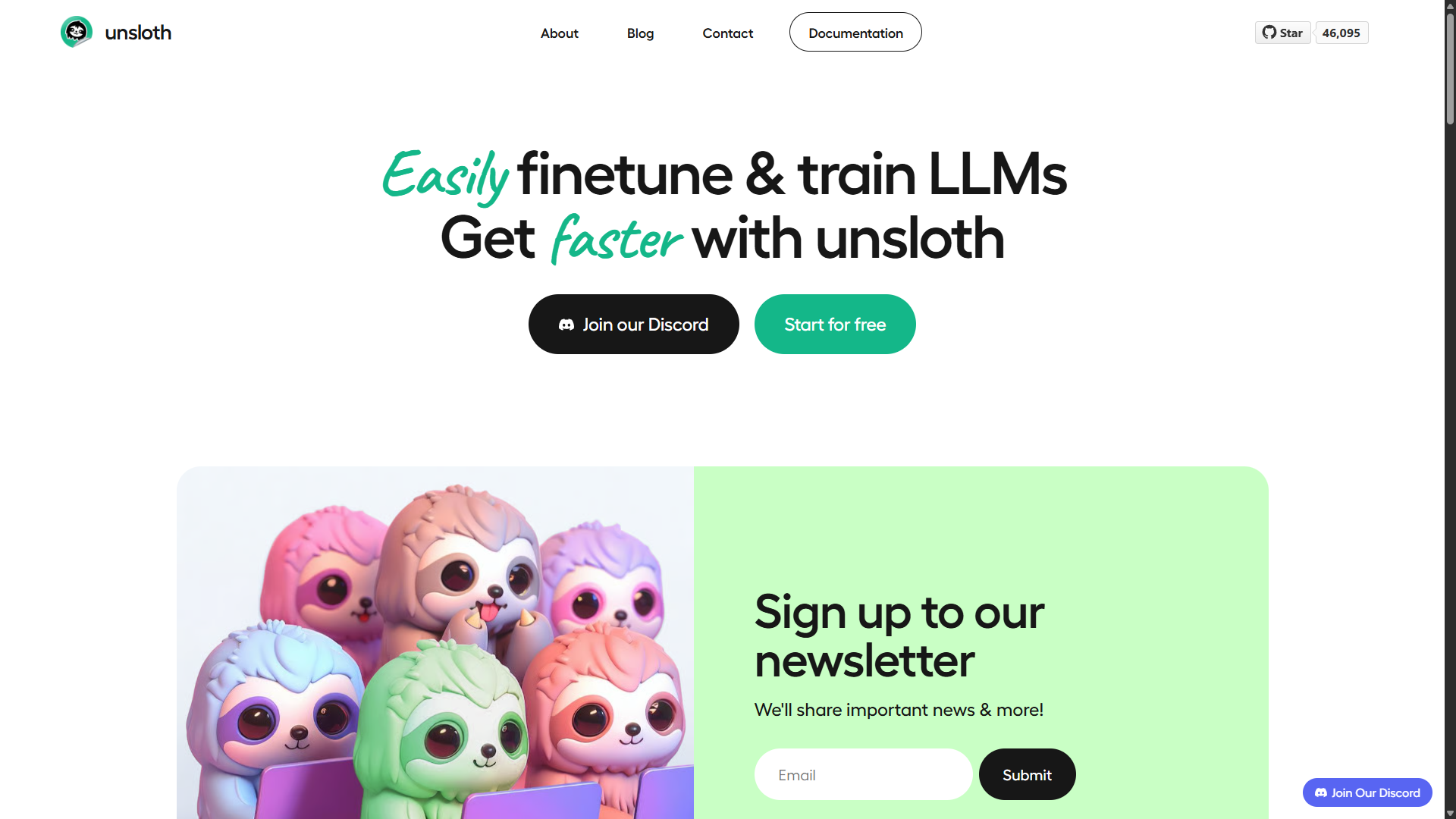
Q、K、V 同一个向量,乘了三组不同的矩阵
- 让“我在找什么”(Q)
- 和“我能提供什么”(K)
- 与“我的内容是什么”(V)
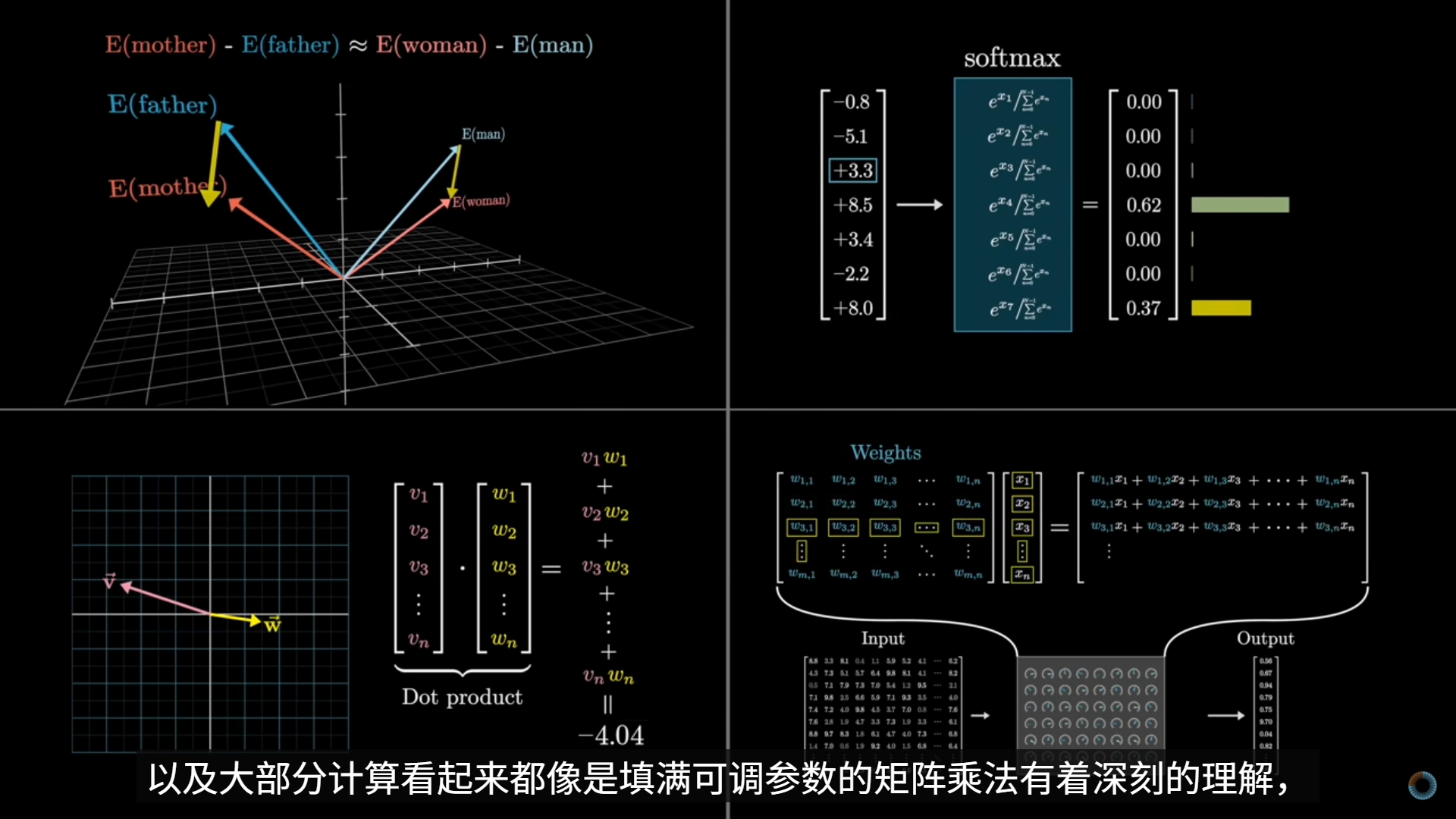
点积(Q·K)
- 衡量“我关心的”和“你提供的”有多对齐
- 本质是向量相似度
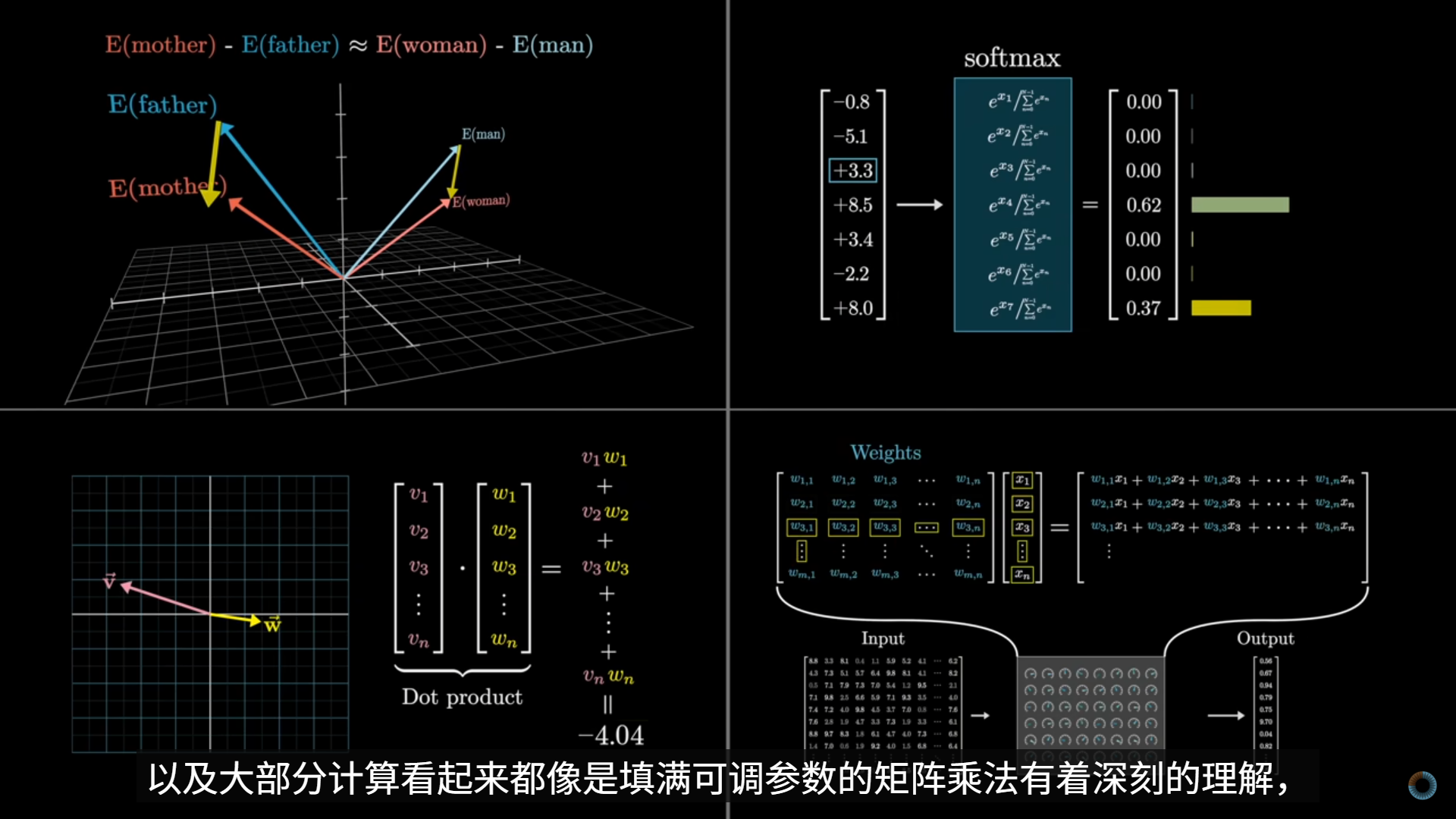
Softmax
- 把“相对相关性”变成“注意力分配比例”
- 保证:
- 全是正数
- 和为 1
加权求和 V
- 信息不是选一个
- 而是按重要性混合
多头 Attention = 同一句话,用多套“关注标准”看
- 一头更偏语法
- 一头更偏语义
- 一头更偏位置关系
RNN | Attention |
顺序传播 | 全连接 |
信息会衰减 | 直接访问 |
不能并行 | 天然并行 |
记忆隐式 | 关系显式 |
- 举例——mole


- Q K V





- Masking 遮掩

- Multi-headed attention

- Author:沈林曦
- URL:https://blog.aibhtt.com/article/llm/learning/3Blue1Brown/chapter6
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts