type
Post
date
Dec 12, 2025
slug
llm/learning/3Blue1Brown/chapter1
summary
3Blue1Brown LLM 相关视频的笔记
status
Published
tags
LLM
AI
category
技术茶点
icon
password
3Blue1Brown LLM 相关视频的笔记
3Blue1Brown YouTube 主页



But what is a neural network? | Deep learning chapter 1
按照时间顺序梳理记录了一些关键节点
- 提出要解决的问题 首先提出了一个直观问题:如何让计算机识别一张手写的数字“3”。通过这一问题,视频以高度视觉化的方式展示了神经网络如何处理输入、传播信息,以及“机器学习”这一过程的基本思想。

- 多层感知机(Multilayer Perceptron, MLP) 随后引入了多层感知机(Multilayer Perceptron, MLP)这一模型。MLP 是最简单、也是最基础的一种前馈人工神经网络(Feedforward Neural Network),由多个层次的神经元(节点)组成,通常包括:输入层、一个或多个隐藏层、以及输出层。信息只沿着层与层之间单向传播,不存在循环结构。

- 与神经结构进行类比阐释
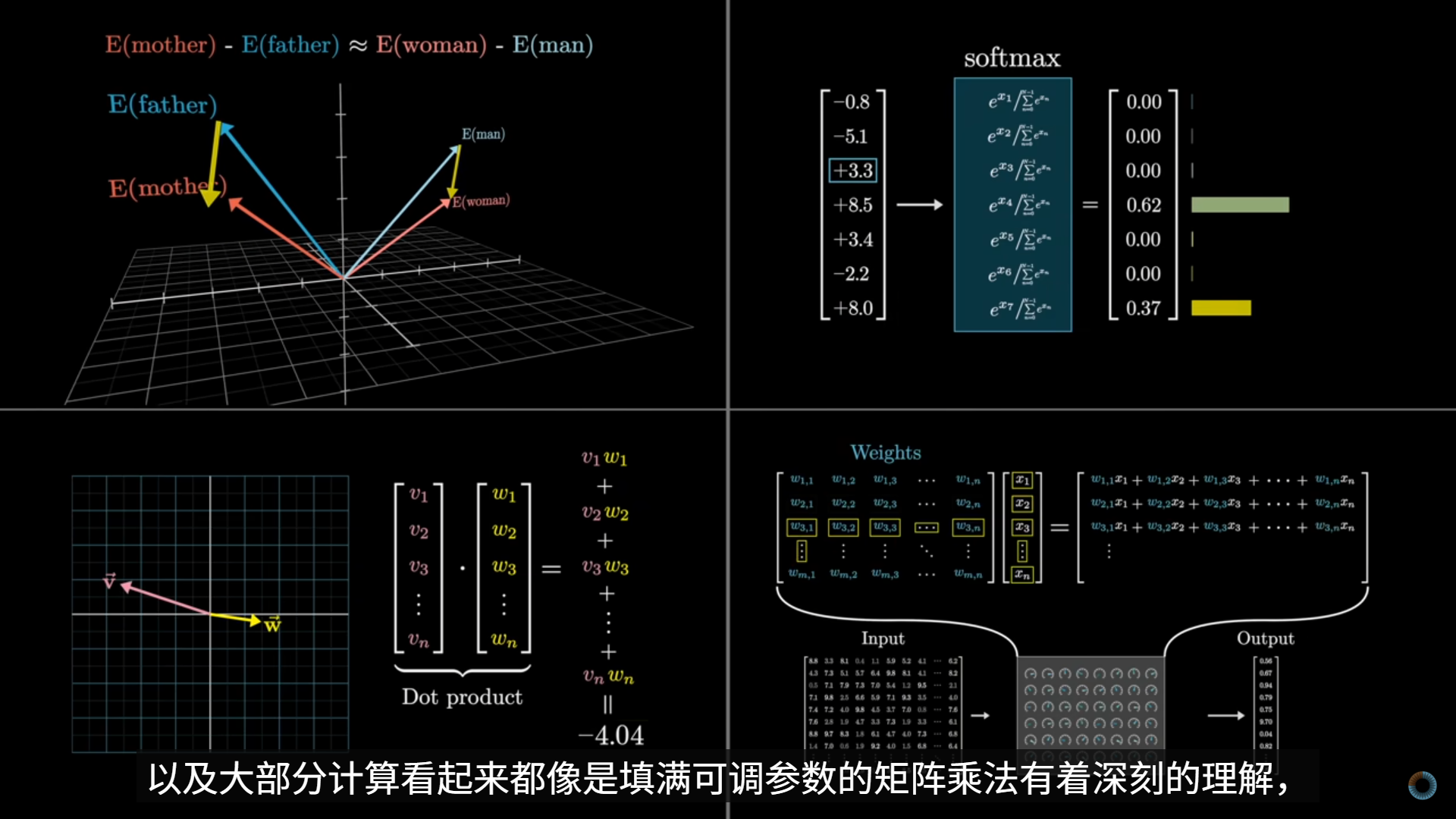
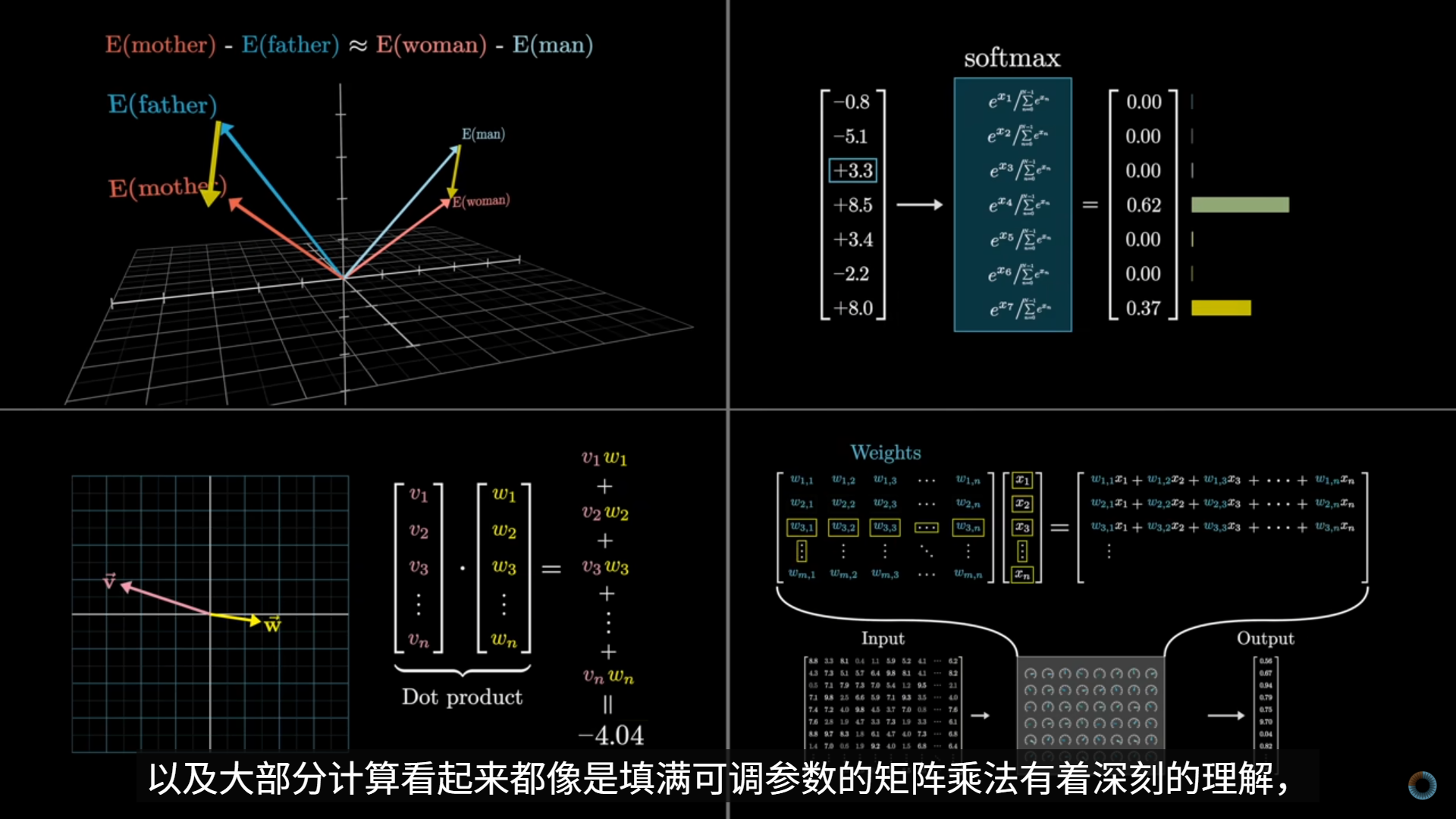
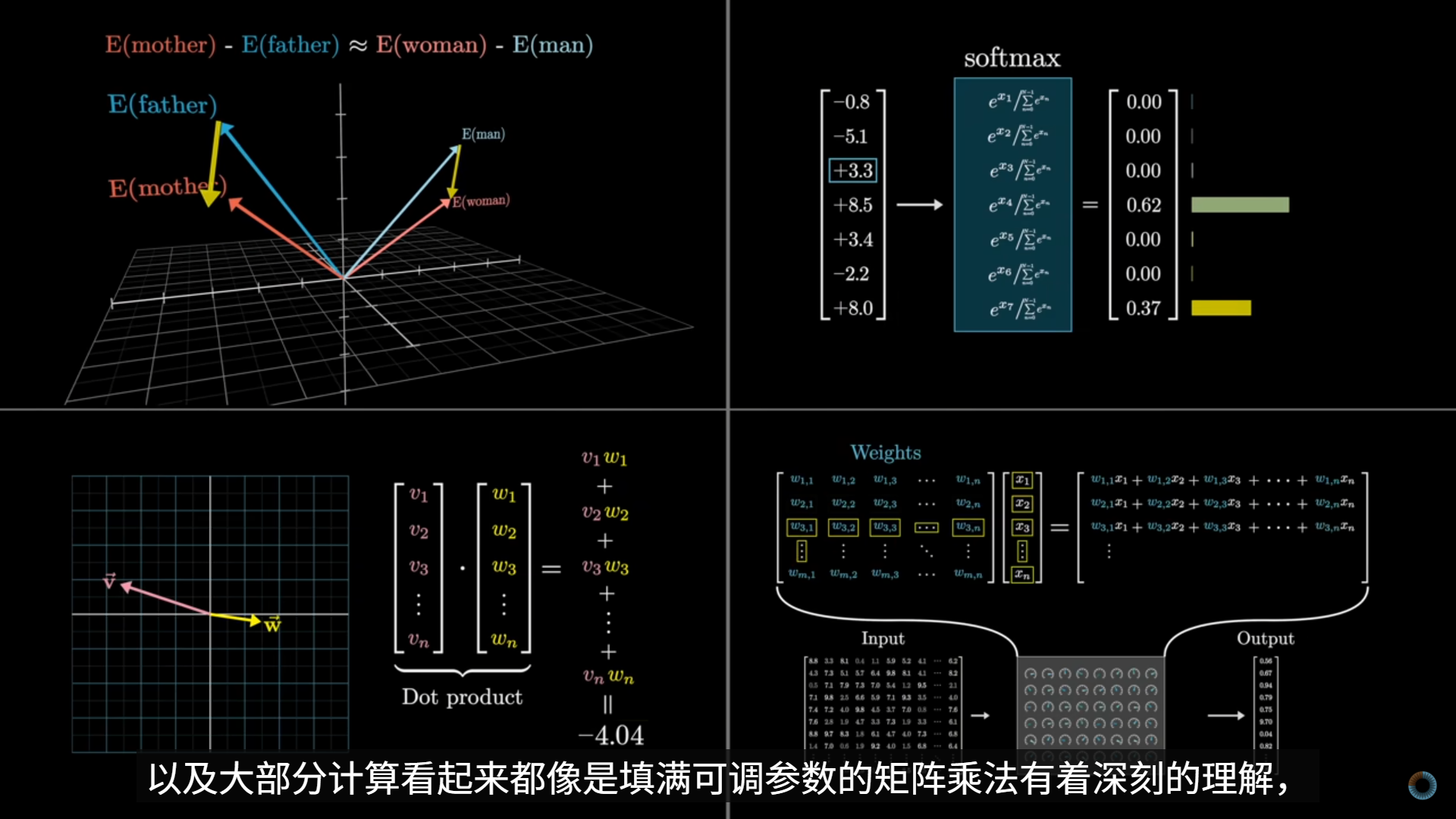
视频将神经网络中的“神经元”与大脑神经结构进行了类比说明:对于一张 28×28 的手写数字图像,可以将每一个像素视为输入层中的一个神经元,其数值表示该像素的灰阶强度,通常被归一化到0–1之间;数值越大,表示该像素越接近白色(或在某些数据集中越接近黑色,取决于定义)。
需要注意的是,这种“神经元”的说法更多是一种数学与工程上的抽象,并不等同于真实生物神经元;在本质上,每一个神经元更接近于一个可学习参数的数学函数。
- 介绍了神经网络的结构 输入层由 784 个神经元构成,对应 28×28 的图像像素;输出层包含 10 个神经元,分别对应数字 0–9,每个神经元的输出可理解为该数字的“匹配程度”或“置信度”;在输入层与输出层之间,存在若干隐藏层。


- 神经网络的核心 神经网络的核心在于:每一层神经元的激励值(activation)是由上一层所有神经元的激励值通过一组参数化的函数共同决定的。因此,输入层中 784 个像素值,经过逐层变换,最终决定输出层中 10 个神经元的激励模式。

- 隐藏层是如何工作的?
视频进一步讨论了我们期望隐藏层如何工作:在直觉上,可以将隐藏层理解为逐步学会对数字笔画、局部结构等特征的拆分与组合,这种过程在一定程度上类似于自然语言处理中对单词或子结构的抽象(例如 token 级别的表示)。
但需要强调的是:神经网络并不会被显式告知“这是笔画”,这些特征并非人为设计,而是通过优化目标在训练过程中自发涌现(emerge)的中间表示。


- 权重参数(weight)、偏置(bias)、Sigmoid 激活函数
随后讲解了连接神经元之间的参数:输入层的 784 个神经元与后续每一个神经元之间的每一条连接线,都对应一个权重参数(weight)某一神经元会对上一层所有神经元的激励值进行加权求和,并在此基础上加入一个偏置(bias)
偏置项的作用是提供一个可调节的“门槛”,使得神经元不必在所有输入为零时输出零,从而增强模型的表达能力。
加权求和的结果会被送入 Sigmoid 激活函数,将输出压缩到 0–1 区间,使其可以被解释为激励强度或概率意义上的值。

- Learning 的本质 在一个包含两层隐藏层、每层 16 个神经元的简单网络结构下,整个网络中大约存在13002 个可训练参数(包括权重与偏置)。学习(Learning)的本质,就是在数据与目标约束下,通过算法自动寻找这一高维参数空间中“表现良好”的参数组合。

- 如何计算 为了在大规模参数和神经元数量下高效计算,单个神经元的计算会被统一表示为矩阵与向量运算,再结合逐元素作用的激活函数(如 Sigmoid),从而实现整层神经元的并行计算。 这一步是神经网络能够在 GPU / TPU 上高效训练、并最终发展为大规模模型(如 Transformer 和 LLM)的工程基础。
- 这一行公式完整描述了一整层神经元的前向传播(forward propagation),也是深度学习中所有模型(包括 CNN、Transformer、LLM)在数学结构上的共同起点。
- 完成了从“神经元直觉”到“层级数学表达”和“可执行代码”的统一





- “神经元”即函数
视频最后对“神经元”这一概念进行了纠偏:与其将神经元理解为某种拟人的结构,不如将其视为一个数学函数——它接收上一层所有神经元的输出,经过线性变换与非线性映射,输出一个介于 0–1 之间的数值;从这个角度看,整个神经网络本身也可以被视为一个复杂函数的组合。

- 抛出下一章要讨论的问题
最后,视频抛出了一个关键问题:神经网络究竟是如何仅通过读取数据,就能自动学会调整权重和偏置的?这一问题直接引出了后续内容——损失函数、反向传播(Backpropagation)以及梯度下降,也是现代大模型训练机制的理论起点。
- Author:沈林曦
- URL:https://blog.aibhtt.com/article/llm/learning/3Blue1Brown/chapter1
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts